A Solution from Purgatory (for the Matrix from Hell)
 This post attempts to recount some of my thought process which eventually (more than a year later) lead to the Matrix from Hell puzzle I posted about a few days ago. If you don’t want to know my answer, don’t read the rest of this post. My final solution is at the bottom.
This post attempts to recount some of my thought process which eventually (more than a year later) lead to the Matrix from Hell puzzle I posted about a few days ago. If you don’t want to know my answer, don’t read the rest of this post. My final solution is at the bottom.
…
You have been warned.
~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~
Below is a list of my general thought process and the main ideas/revelations/halucinations that I know helped me to my solution. An annotated matrix is at the bottom with some of the ideas highlighted in different colors.
- Should indices start at 0 or 1?
- Values along either axis count up by 1 in both directions when the other =0
- Values are duplicated over the f(x)=y axis –> Order of indices given to function is inmaterial since they can be swapped
[The RED 5 can be seen duplicated over the diagonal] - Calculation of max/min index is O(1) so stop worry about it and “forget” the bottom half of the matrix (assume X>= Y)
- Values generally increase as they go right/down but not always
- f(x,x)=0, f(x,0)=x
- Values are symmetrical perpendicular to f(x)=y IFF the bounding square in question is a power of 2
- “Quad” patterns can be seen repeating for every power of 2. In each “Quad” the top left quadrant is the same as the bottom right and the top right is the same as the bottom left.
[Each “Quad” of the example matrix is outlined in BLUE with the quadrants in LIGHT BLUE. PINK shows the repetition] - power of 2 repeating nature of the values leads to thinking of binary trees
- binary trees leads to thinking about a possible solution which could run in O(log2 n) time:
- In a nut shell, for a given (X,Y), algorithm would find smallest boudning power of 2 including X and would walk back “Quad”s by each successivly smaller power of 2 “Quad” until the last one is met. For each “Quad” determine which quadrant the value lives in and remap to root values.
- Debate if this would really work for large numbers and if it could be reduced to constant time function by math that I have forgotton from college/HS
- Dismiss b/c I can’t remember a way and base idea is > O(1)
- Binary trace back algorithm idea makes me realize that it can be also looked at as the “binary” representation of a number (e.g. 01011011010) where each 1 represents a “Quad” where the value was in the upper right or bottom left and vica-verca.
[Following the matrix value at (5,6) can be seen ORANGE. The value 3 is in the bottom right of the 1st “Quad”, then BL, & TR. {BR BL TR} => {101} => {3}] - Remembered that f(x,y)=0 IFF x==y …. which means that difference between X and Y is important to value of f()
- Eureka!
- F(X, Y) = X xor Y
- solution typed above in white on white to protect the innocent. highlight to view.

That is it. I never said it was pretty or made any sense.
Matrix Puzzle From Hell or: How I Learned to Stop Worrying and Love the Patterns
 The Stage
The Stage
About a year ago, Mr. King (@Adkron) posed a math puzzle on our team’s whiteboard first thing one morning. The problem seemed at the same time very complex and strangely simple. Amos said that he had found it surfing the web the night before and that it was from some company’s interview or resume-submitting questions.
After several passionate whiteboarding sessions including members of our team, and any poor souls who walked by (I believe Mr. Young falls into this group), no one had a solution. Eventually the whiteboard was clearred for more “important” work but the puzzle lingered with me. On several occasions over the past year I have redrawn the matrix on a pad of paper and spent and hour or two trying to decipher the patterns and make sense of the answer tickling at edge of my brain.
This past week, while drifting off to sleep, the puzzle popped back into my head. After a few moments a number of ideas I had had months before fell together in just the right way for me to FINALLY figure out a solution. Eureka! (I mentally shouted) and got out of bed to find a piece of paper to work through some more examples and prove myself right.
The Puzzle
Given a 2D matrix such that each cell’s value is defined as follows:
>> The smallest non-negative integer not already present to the “left” or “above” <<
Determine an constant time function ( O(1) ) which given X and Y indices will return the value of the matrix cell at (X,Y).
For the visual people in the crowd, the top left corner or said matrix looks something like this:

First 8x8 cells of matrix puzzle
The picture only shows the top 8×8 of the defined matrix as an example. We can see that whatever f(x,y) you come up with needs to equal the following example values
f(0,0) = 0
f(1,0) = 1
f(2,0) = 2
f(3,0) = 3
f(3,1) = 2
f(3,2) = 1
……
The real key here is that the solution needs to function in constant time: O(1). This means that computing the matrix value at (6,3) should be the same cost computationally as computing the matrix value at (10000000,4500005).
Anyone can write a program to compute the whole matrix out to your point (in theory) but can you come up with a better solution? In less than a year?
The Solution
Not just yet. I will post my thought process and eventual solution soon in a separate post.
** I didn’t think of this puzzle, nor guarantee that I am remembering it correctly **
** If you know who did or have any corrections, please leave a comment below **
Popping a Register from a Stack: QuickPiet Macros

Piet slide deck on Prezi.com
And now for something completely different …
Back in March I went crazy. I spent WAY too many nights hacking in David Morgan-Mar’s Piet programming language. Piet programs are bitmaps which are executed as a “pointer” traverses the image. To make matters even worse, the underlying native commands only allow the program to use a single stack for storage. Nothing else. The original goal was to learn enough to put together an interesting and funny presentation for the Esoteric and Useless Languages April Fool’s Day meeting of the Lambda Lounge user group here in St. Louis. In the end I think I succeeded but you can be the judge for yourself. My slide deck can be found Prezi.com and a video of my talk can be found on blip.tv (Thanks to Alex Miller for recording it). You can also find some other posts on Piet and the subset language I created QuickPiet here.
The most surprising outcome of all that image editing and eye-crossing stack tracing was a completely inappropriate desire to build more and more complex programs with the very basic tools [Quick]Piet offers. I became consumed with thoughts of how to replicate higher level ideas and abstractions built on top of a single stack. I am sure most of my work could easily be explained and improved upon in any Finite Automata or Language Theory textbook … but I wanted to do it myself.

My Piet Presentation @ Lambda Lounge (blip.tv)
When you only have a stack to work with, you realize you don’t have much. Our ability as software developers to add layers of abstraction is such a powerful tool. Without abstractions the entire complexity of an application has to fit into a developer’s head. With only a stack, even small tasks are difficult because the entire state of the application has to be maintained as each command is execute. I quickly realized that I needed a way to have stationary registers or variables that could hold data throughout the life-cycle of a program without me needing to know where they were on the stack constantly.
My solution was to keep track of the size of the stack. Simple no?
Imagine a stack full of values. The only constants of a stack are the top and bottom. If we want to hide some registers inside our stack, it makes sense to keep them at one of the ends. Only one problem: the top is highly volatile and we have no idea where the bottom is. My idea was to keep the current size of the stack as the top most element on the stack at all times. If you always knew the top value was the “size” of the stack, then when you first start your application you could stash a few extra values down in the “negative” and use these values as registers/variables throughout your application. This leads to one big hurdle: how can we keep track of the stack size as we execute our program?
After a lot of soul searching and too many crumpled of pieces of notebook paper to count I conjectured that you could recreate all of the native stack commands that Piet offers as macros that would maintain and update the stack size as you went. A Piet Developer (are there any other than me?) would simply need to work with these macros instead of the native commands and could build out new macros which would leverage that stack size to retrieve and store values from the registers. Abstraction for the win.
Code examples from my proof of concept JavaScript implementation
this.push_ = function(x) { // macro stack-size-aware PUSH command
this.push(1);
this.add(); // update stack size value
this.push(x); // perform actual PUSH
this.push(2);
this.push(1);
this.roll(); // roll new value to below stack size
};
this.dup_ = function() { // macro stack-size-aware DUP command
this.push(1);
this.add(); // update net stack size value
this.push(2);
this.push(1);
this.roll(); // hide stack size value under top stack value
this.dup(); // perform actual DUP (creates new duplicate value on top of stack)
this.push(3);
this.push(2);
this.roll(); // roll up stack size value from its hiding place
};
Several hours later I had built macros which mimicked all of the more basic commands which would preserve the stack size value (e.g. PUSH, POP, ADD, SUB, etc). Each macro was 5 – 10 native commands depending on the number of stack values changing at a time. The hard part came when I wanted to build a new ROLL command. This command differed from all of the others since the area of the stack effected by executed the command depended on the input values. All of the other commands effected a fixed number of values (e.g. PUSH always nets a single new value on the stack). So while most macro-commands could be built with useful assumptions about how many values were changing, ROLL needed to effect a variable amount of the stack to varying depths. When it was all said and done, my new ROLL command was more than 30 commands!
this.roll_ = function() {
// decrement counter
// # -> (# - 2)
this.push(2);
this.sub();
// find roll offset (iterations mod depth)
// a b # -> # a (b % a) (b % a)
this.push(3); // a b # 3
this.push(1); // a b # 3 1
this.roll(); // # a b
this.push(2); // # a b 2
this.push(1); // # a b 2 1
this.roll(); // # b a
this.dup(); // # b a a
this.push(3); // # b a a 3
this.push(1); // # b a a 3 1
this.roll(); // # a b a
this.mod(); // # a (b % a)
this.dup(); // # a (b % a) (b % a)
// find depth for count (offset + 2 + 1)
// o -> (o + 3)
this.push(3); // o 3
this.add(); // (o + 3)
// roll count to proper depth within roll area
// # a b X -> # ...X... a b
this.push(4); // # a b X 4
this.push(3); // # a b X 4 3
this.roll(); // a b X #
this.push(2); // a b X # 2
this.push(1); // a b X # 2 1
this.roll(); // a b # X
this.push(1); // a b # X 1
this.roll(); // # ...X... a b
// increase depth by one
// a b -> (a + 1) b
this.push(2); // a b 2
this.push(1); // a b 2 1
this.roll(); // b a
this.push(1); // b a 1
this.add(1); // b (a + 1)
this.push(2); // b (a + 1) 2
this.push(1); // b (a + 1) 2 1
this.roll(); // (a + 1) b
// roll to finish?
this.roll();
};
Since a ROLL command has a variable depth the basic solution is to calculate how deep things are going to end up (iterations mod depth) and hide the stack size value in the middle of the roll’s depth and roll to a depth one greater than originally requested. This should leave the stack size value at the top of the stack once again and everything else where it should be.
You can find my implementations of all macros in this gist hacked together in a small html file with JavaScript. I might be crazy, but damn it I did it. With these macros registers are possible (assuming you know how many registers you need at “compile time” — although an infinite amount is theoretically possible). It seems like this is the first big step to a proof of Piet’s Turing completeness …. but that is a task for another day.
mario math – part 2
To calculate Mario’s position with KEY_RIGHT pressed down continuously for n frames:
let 
at frame 1:
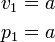
at frame 2:
![\begin{align} & v_2 = a(.89) + a \\ & p_2 = a + [a(.89) + a] \end{align}](https://twoguysarguing.files.wordpress.com/2009/08/pcalc_eqn3.png?w=720)
at frame 3:
![\begin{align} & v_3 = (a(.89) + a).89 + a \\ & p_3 = a + [a(.89) + a] + [(a(.89) + a).89 + a] \end{align}](https://twoguysarguing.files.wordpress.com/2009/08/pcalc_eqn4.png?w=720)
at frame 4:
![\begin{align} & v_4 = ((a(.89) + a).89 + a).89 + a \\ & p_4 = a + [a(.89) + a] + [(a(.89) + a).89 + a] + [((a(.89) + a).89 + a).89 + a] \end{align}](https://twoguysarguing.files.wordpress.com/2009/08/pcalc_eqn5.png?w=720)
If you multiply everything through, a pattern starts to emerge:

So we can say that in general, Mario’s position after n frames will be:
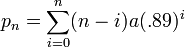
But we’d like a formula we can evaluate in O(1), so massaging the equation a bit we get:

Both of sums in the above equation, we have identities for:
 and
and 
Of which the second one is kind of convoluted, but allows us to come up with:

Which can then write in Java as:
public float positionAfter(float accel, int nFrames) {
float term1 = n * (1 - Math.pow(.89, nFrames + 1)) / .11;
float term2 = (Math.pow(.89, nFrames + 1) * (-.11 - 1) + .89) / .2079;
return a * (term1 - term2);
}
The (.89) term is friction (I think?) and on the ground the code uses that value. In the air, the dynamics and equations are the same, but use a different coefficient of friction: (.85). The initial acceleration of a jump is vastly different, though, so I’ll tackle that in the next Mario Math installment.
mario math
To calculate Mario’s velocity, with KEY_RIGHT pressed down continuously for n frames:
let  (1.2 if KEY_SPEED is held down as well)
(1.2 if KEY_SPEED is held down as well)
at frame one, then, your velocity 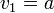
frame 2: 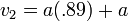
frame 3: 
frame 4: 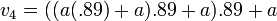
which, if you multiply through, looks like this:

Which makes it a bit easier to generalize Mario’s velocity at any frame n:

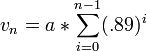
we know from paying attention in high school wikipedia that:

however, our sequence only goes to n-1 frames. It’s missing the last term:

subtracting xn from both sides

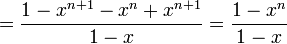
which we could have maybe figured out faster if we had remembered this identity:

replacing the lower m with 0 and upper n with n-1 we get:

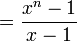
which multiplied by  is what we found earlier.
is what we found earlier.
and so mario’s velocity after n frames of acceleration is:
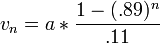
which can be calculated in constant time by this Java function:
public float velocityAfter(float accel, int nFrames) {
return accel * ((1 - Math.pow(0.89, nFrames)) / 0.11);
}
Whew.
Thanks to Heath Borders and my co-blogger Ben for working this out on a whiteboard with me.


1 comment